1. 引言
项目上选用 dpdk 收包,因此对其做个初步了解,特此记录。
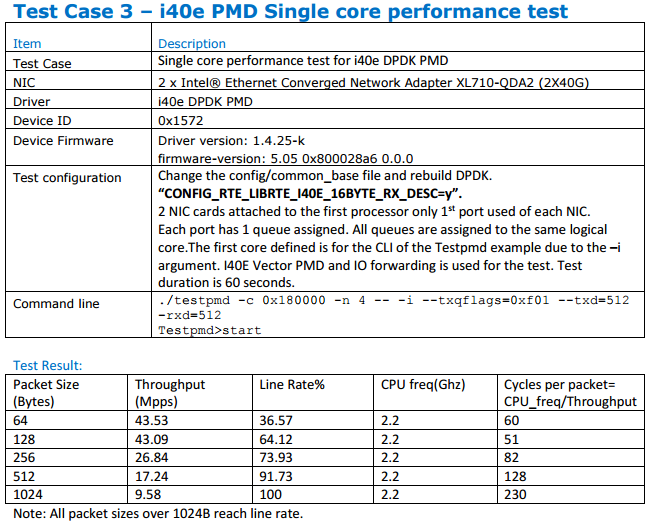
DPDK 全称 Data Plane Development Kit,是 Intel 推出的高速数据包处理套件,依据官方性能测试报告 DPDK 17.05 Intel NIC Performance Report ,单核性能可达到如下程度:
DPDK 主要提供以下4个库:
- 多核架构(multicore framework)
- 内存巨页(huge page memory)
- 环形缓冲区(ring buffers)
- PMD驱动(poll-mode drivers for networking , crypto and eventdev)
2. 多核架构
DPDK 在启动时,先分析系统的 CPU 属性,根据系统默认状态生成一一绑定的映射表(用户可以根据需求修改)。
每个 CPU 属性如下:
class core{
lcore_id; //逻辑核 id
core_id; //物理核 id
socket_id; //NUMA节点 id
}
class core coremap[] //所有逻辑核的映射表
在启动服务器的时候,DPDK 选取一个逻辑 CPU 做为主核,接着启动其它 CPU 做为从核,所有线程都根据映射表做 CPU 绑定。控制核主要完成 pci、内存和日志等系统的初始化;从核启动后,等待主核初始化完毕后挂载业务处理入口, 然后运行业务代码。
流程示意图如下:

注:对象(如 memory zones, rings, memory pools, lpm tables 和 hash tables)初始化应该作整个应用初始化的一部分在主核完成。对象的创建和初始化过程并不是线程安全的,当然,一旦初始化完成,就可以在多个线程上安全并发了。
3. 巨页
Linux 在内存管理中采用受保护的虚拟地址模式,代码中地址分为3类:逻辑地址、线性地址、物理地址。程序使用具体内存简单说就是逻辑地址通过分段机制映射转化为线性地址,然后线性地址通过分页机制映射转化为物理地址的过程。分段机制是 IA32 架构 CPU 为了支持访问更大的内存地址空间引入的,并不是操作系统寻址方式的必然选择。Linux 在实现中绕过了分段机制,逻辑地址和线性地址相同。分页机制主要实现虚拟存储器,是操作系统为应用程序提供的一个不依赖于硬件的存储管理平台,但是各个硬件平台的实现各不相同。为了最大化兼容不同的硬件实现,Linux 采用四级页表结构,如下图所示:
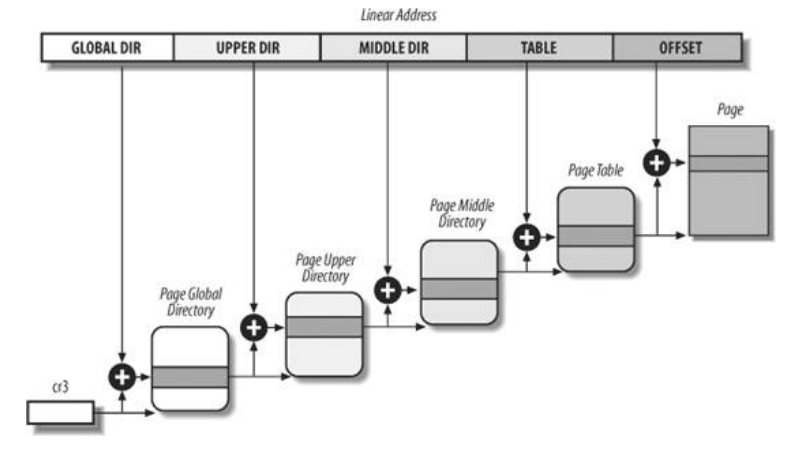
为了减少在查询页表过程中带来的内存访问延迟,CPU 在硬件上对页表做了缓存,就是 TLB 缓冲区。线性地址先从 TLB 获取高速缓存内存,如果不存在就从内存表获取,如果有直接的映射,直接从内存读取,没有则产生缺页中断,重新分配物理内存,或者从硬盘上将 swap 读取。
4K 的页表是 Linux 针对一般情况得出的合适大小,然而对于特殊应用可以通过扩大页表面积提高内存使用效率。DPDK使用 hugepage (2M/1G…)可以有效减少 TLB 表项,减少页表开销的同时提高 TLB 命中率,提升访问速度。另外,hugepage 这种页面不受虚拟内存管理影响,不会被替换出内存,而普通的 4k page 如果物理内存不够可能会被虚拟内存管理模块替换到交换区,降低访问速度。
DPDK 提供了基于 hugepage 的共享内存机制,使得多进程物理地址相同,其虚拟地址也相同。这就和多线程之间共享地址空间是一样的了,采用DPDK的基础库,多进程之间不需要共享的部分可以使用普通内存(libc malloc,静态区和栈区),安全隔离;需要共享的部分可以采用 DPDK hugepage 内存,通过特殊的映射共享虚拟地址。
4. 环形缓冲区
区别于传统的无限大小的链式结构,DPDK 的队列管理模块 rte_ring 具有以下特征:
- 大小固定,指针存储在表中
- 无锁
- 支持单/多消费者出队列
- 支持单/多生产者入队列
- 支持按块出入队列,一次操作指定个数的对象(个数不足时,支持直接 fail 和操作最大可用数目两种模式)
相较链式结构而言,具有以下优势:
- 速度快 仅需要一次 sizeof(void *) 的 Compare-And-Swap 操作,比多次 double-Compare-And-Swap 具有明显优势。only requires a single Compare-And-Swap instruction of sizeof(void *) instead of several double-Compare-And-Swap instructions.
- 比一个完整无锁队列实现简单
- 可以按块初入队列 因为指针都是存在表里的,按块出队列比链式结构有更少的 cache misses,与单个对象出队列的花费相当。
当然也有这些劣势:
- 大小固定
- 在内存方面环形比链式结构有更多花费 空环也至少包含 N 个指针。
每个环形缓冲区都有一个独一无二的名称。若以相同名称创建第二个 ring, rte_ring_create() 接口将直接返回 NULL。
DPDK 的内存池管理内部就使用了 ring。ring 还可以用于 DPDK 应用间的通信。

上图是一个简单 ring 示例。可以发现,每个 ring 有两对指针:一对 prod_head/prod_tail 提供给 producers,一对 cons_head/cons_tail 提供给 consumers。
5. PMD
传统 Linux 网络协议处理过程:
硬件中断 --> 取包分发至内核线程 --> 软件中断 --> 内核线程在协议栈中处理包 --> 处理完毕通知用户层 --> 用户层收包 --> 网络层 --> 逻辑层 --> 业务层
首先网卡通过中断方式通知协议栈对数据包进行处理。协议栈先对数据包的合法性进行必要的校验,然后判断数据包目标是否为本机,满足条件则会将数据包拷贝一份向上递交给用户层来处理。不仅处理路径冗长,还需要从内核到应用层进行一次拷贝。
DPDK 对该过程做了特殊处理:
硬件中断 --> 放弃中断流程 --> 用户层通过设备映射取包 --> 进入用户层协议栈 --> 逻辑层 --> 业务层
DPDK 针对 Intel 网卡实现了基于轮询方式的 PMD(Poll Mode Drivers)驱动。该驱动由 API、用户空间运行的驱动程序构成。除了链路状态通知以外,该驱动使用无中断方式直接操作网卡的接收和发送队列。目前 PMD 驱动支持 Intel 的大部分 1 Gigabit、10 Gigabit 和 40 Gigabit 的网卡。PMD 驱动从网卡上接收到数据包后,会直接通过 DMA 方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理。
概括而言有以下三个优化,在网络密集型场景下有更好表现:
-
拦截中断,不触发后续中断流程,并绕过协议栈
通过 UIO 重设内核中断回调行为,绕过协议的后续的处理流程。
-
无拷贝收发包,减少内存拷贝开销
DPDK的包全部在用户控件中使用内存池管理,内核控件与用户空间的内存交互不用进行拷贝,只做控制权转移。
-
用户自定义协议栈,可以降低复杂度
DPDK 对包处理提供了两种模型:
- run-to-completion 同步模型。数据包接收到指定端口的收包队列后,由同一 CPU 处理,并被传给某一端口的发包队列以便转发。
- pipe-line 异步模型。一个 CPU 接收一个或多个端口的数据包至一个收包队列,由其它 CPU 处理完毕后传给某一端口的发包队列以遍转发。
DPDK 支持 NUMA(Non-Uniform Memory Access,非统一内存访问)技术,允许 CPU 和 网络接口 使用本地内存以获得更高性能。因此接口的内存池最好从本地内存中申请。并且在允许的情况下,申请的 buffers 只在本地处理,不传给远端核心,保证最佳性能。